めもめも ...〆(。_。)
認知心理学・認知神経科学とかいろいろなはなし。 あるいは科学と空想科学の狭間で微睡む。

×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
ひさしぶりに古典再訪シリーズ。
これでたぶん3つめぐらいだろうからそろそろシリーズを名乗ってもおかしくないだろう。
とはいえ不定期だからあてにはならんな。
それはともかく、今回はDual-coding theryですよ。
これはPicture Superiority Effectの(http://azcog.blog.shinobi.jp/Entry/441/)を参照してもらったほうがよい話。
この2つは切り離せないというかコインの裏表というか、まあDual-coding theoryが原因でPicture Superiority Effectが結果、とPaivioらは考えているわけで。
教科書的に言えば片方に言及するときもう片方は勝手に内包されていると仮定されてるのかな。
ただ、Picture Memoryをがっつりやってるひとたちならわかると思うけども、常にPicture Superiorityがあるわけでもないし、encodingはdualってだけでなくあらゆるモダリティで行われていると考えるのがふつうではないかな。
まあヒトは視覚優位なとこがあるし、代表的なモダリティを拾うのであればdualって言っても問題はないかも?いやさすがにちょっとざっくりしすぎか?
とりあえず、
Paivio, A., & Csapo, K. (1973). Picture superiority in free recall: Imagery or dual coding. Cognitive Psychology, 5, 176-206.
http://www.sciencedirect.com/science/article/pii/0010028573900327
で紹介されている分をざっくりざっくりまとめると以下のようになる。
ここでは、はっきり「theory」といわずに「dual-coding approach」と言ってるので、この時点ではtheoryとしての確立はしていないけども、この論文の実験はdual-codingをtheoryとするための検証という側面もあるので、この論文をdual-coding theoryの代表と考えてもいいのかな。
とりあえず以下まとめ。
情報処理は、言語みたいなsymbolによる過程と、言語に依存しないimageryによる過程の2種類がある。
この2つは別個に処理されるけども、記憶の諸過程(符号化とか貯蔵とか検索とか)においてちゃんと関連付けされている。
んで、imagery過程は具体的な事象のrepresentationに特化してて、symbol過程は言語などの抽象的な過程に特化している。
画像なんかはimagery過程とsymbol過程両方で処理できて、一方のrepresentationをもう一方のにおきかえることも可能で、手がかり増えるから記憶パフォーマンスがよい。というのがPicture Superiority Effectだったわけですね。
モダリティごとの処理というのはBaddeleyのワーキングメモリモデルなんかにも引き継がれていくわけですが、dual-codingの考え方単体でもそれなり生き延びている様子。
まあ何よりもびっくりなのがPaivioもBaddeleyも現時点で生きてることですよ。
教科書的人物が生きてるのってなんかすごいよねー。たぶん本人らにしてみれば「何抜かす若造め」ってもんなんでしょうけど。
実際dual-codingを扱ったものとしては、以下に出すようにいろいろあるようす。
http://www.ncbi.nlm.nih.gov/pubmed/21656220
は本人含む研究グループで、ERPつかっての検証。
本人以外でも
http://www.ncbi.nlm.nih.gov/pubmed/1141833
などでdual-codingの検証はなされているようす。
展開としては、
http://www.ncbi.nlm.nih.gov/pubmed/21585499
はmental imageryにおける空間情報のdual-codingの話。
http://www.ncbi.nlm.nih.gov/pubmed/8794554
はちょっと変わってて、嗅覚に関するdual-codingの話。
ワーキングメモリとの関連も、
http://www.ncbi.nlm.nih.gov/pubmed/17932697
のレビューなどにまとめられている。
研究の例を挙げると、
http://www.ncbi.nlm.nih.gov/pubmed/21942734
はギリシャでこどものワーキングメモリと読解能力の関係を調べる上でdual-codingに基づく解釈を行っている。
しかしなんといっても関連が多く論じられているのはSemantic研究で、
http://www.ncbi.nlm.nih.gov/pubmed/8711012
は本人含むグループでPicture namingについてのレビューでdual-codingもその1要素として語られているし、
http://www.ncbi.nlm.nih.gov/pubmed/15893940
は単語のimageabilityに絡めている。
そんなdual-coding絡みのsemantics研究の中でも、「具体性(concreteness)」の効果
に関するものは特に相性がよいようす。
http://www.ncbi.nlm.nih.gov/pubmed/8064248
や
http://www.ncbi.nlm.nih.gov/pubmed/17651011
などが挙げられる。
さらにsemanticsメインじゃなくても、
http://www.ncbi.nlm.nih.gov/pubmed/16861011
のように再認における具体性効果についても絡められておるもよう。
それからcontext availabilityでも援用されているみたい。
http://www.ncbi.nlm.nih.gov/pubmed/16550855
http://www.ncbi.nlm.nih.gov/pubmed/10924219
など。
古典といえど現役なのだなあ。
そいや、dual-coding approachがdual-coding theoryになる境目というか'dual-coding theory'の初出は発見できず。
どうも本っぽいな・・・
Picture Superiority Effectんときに言及した本のうち、1971年の「Imagery and verbal processes.」がそれっぽい?
1986年の「Mental representation: A dual coding approach.」のGoogle books()で見られる限りでは4章タイトルがまんまdual-coding theoryなので、少なくともこれより前であるのは確か。
4章見ると、1971年のやつの考えにさらに手を加えたってことらしいから、これをdual-coding theoryの代表としてもよいかもしれない。
上であげたの以外では、
も候補にあげられそう。
つーかあまぞんにあるんだ・・・すげーなあまぞん。
・・・ただまあ躍起になって初出を探してもあんましメリットがないので、とりあえずdual-coding theoryの引用としてはPaivio (1986)かPaivio & Csapo(1973)でいいのかも・・・
・・・いいのかな?
図書館で本を見つけられたら初出を確認してみてもいいかも。
うーむ。思ったより奥が深いなdual-coding theoryは。
古典もあなどれないぜ!
ーーー追記ーーー
あまぞんさんの
にてなか見!検索が使えることに気づきました。
この中で検索をかけたら、ちゃんとdual-coding theoryって書いてある箇所がありました。
なのでdual-coding theoryの初出は1971年のこの本みたいです。
いやーネットべんりだなー。
謎が解けてよかったよかった。
これでたぶん3つめぐらいだろうからそろそろシリーズを名乗ってもおかしくないだろう。
とはいえ不定期だからあてにはならんな。
それはともかく、今回はDual-coding theryですよ。
これはPicture Superiority Effectの(http://azcog.blog.shinobi.jp/Entry/441/)を参照してもらったほうがよい話。
この2つは切り離せないというかコインの裏表というか、まあDual-coding theoryが原因でPicture Superiority Effectが結果、とPaivioらは考えているわけで。
教科書的に言えば片方に言及するときもう片方は勝手に内包されていると仮定されてるのかな。
ただ、Picture Memoryをがっつりやってるひとたちならわかると思うけども、常にPicture Superiorityがあるわけでもないし、encodingはdualってだけでなくあらゆるモダリティで行われていると考えるのがふつうではないかな。
まあヒトは視覚優位なとこがあるし、代表的なモダリティを拾うのであればdualって言っても問題はないかも?いやさすがにちょっとざっくりしすぎか?
とりあえず、
Paivio, A., & Csapo, K. (1973). Picture superiority in free recall: Imagery or dual coding. Cognitive Psychology, 5, 176-206.
http://www.sciencedirect.com/science/article/pii/0010028573900327
で紹介されている分をざっくりざっくりまとめると以下のようになる。
ここでは、はっきり「theory」といわずに「dual-coding approach」と言ってるので、この時点ではtheoryとしての確立はしていないけども、この論文の実験はdual-codingをtheoryとするための検証という側面もあるので、この論文をdual-coding theoryの代表と考えてもいいのかな。
とりあえず以下まとめ。
情報処理は、言語みたいなsymbolによる過程と、言語に依存しないimageryによる過程の2種類がある。
この2つは別個に処理されるけども、記憶の諸過程(符号化とか貯蔵とか検索とか)においてちゃんと関連付けされている。
んで、imagery過程は具体的な事象のrepresentationに特化してて、symbol過程は言語などの抽象的な過程に特化している。
画像なんかはimagery過程とsymbol過程両方で処理できて、一方のrepresentationをもう一方のにおきかえることも可能で、手がかり増えるから記憶パフォーマンスがよい。というのがPicture Superiority Effectだったわけですね。
モダリティごとの処理というのはBaddeleyのワーキングメモリモデルなんかにも引き継がれていくわけですが、dual-codingの考え方単体でもそれなり生き延びている様子。
まあ何よりもびっくりなのがPaivioもBaddeleyも現時点で生きてることですよ。
教科書的人物が生きてるのってなんかすごいよねー。たぶん本人らにしてみれば「何抜かす若造め」ってもんなんでしょうけど。
実際dual-codingを扱ったものとしては、以下に出すようにいろいろあるようす。
http://www.ncbi.nlm.nih.gov/pubmed/21656220
は本人含む研究グループで、ERPつかっての検証。
本人以外でも
http://www.ncbi.nlm.nih.gov/pubmed/1141833
などでdual-codingの検証はなされているようす。
展開としては、
http://www.ncbi.nlm.nih.gov/pubmed/21585499
はmental imageryにおける空間情報のdual-codingの話。
http://www.ncbi.nlm.nih.gov/pubmed/8794554
はちょっと変わってて、嗅覚に関するdual-codingの話。
ワーキングメモリとの関連も、
http://www.ncbi.nlm.nih.gov/pubmed/17932697
のレビューなどにまとめられている。
研究の例を挙げると、
http://www.ncbi.nlm.nih.gov/pubmed/21942734
はギリシャでこどものワーキングメモリと読解能力の関係を調べる上でdual-codingに基づく解釈を行っている。
しかしなんといっても関連が多く論じられているのはSemantic研究で、
http://www.ncbi.nlm.nih.gov/pubmed/8711012
は本人含むグループでPicture namingについてのレビューでdual-codingもその1要素として語られているし、
http://www.ncbi.nlm.nih.gov/pubmed/15893940
は単語のimageabilityに絡めている。
そんなdual-coding絡みのsemantics研究の中でも、「具体性(concreteness)」の効果
に関するものは特に相性がよいようす。
http://www.ncbi.nlm.nih.gov/pubmed/8064248
や
http://www.ncbi.nlm.nih.gov/pubmed/17651011
などが挙げられる。
さらにsemanticsメインじゃなくても、
http://www.ncbi.nlm.nih.gov/pubmed/16861011
のように再認における具体性効果についても絡められておるもよう。
それからcontext availabilityでも援用されているみたい。
http://www.ncbi.nlm.nih.gov/pubmed/16550855
http://www.ncbi.nlm.nih.gov/pubmed/10924219
など。
古典といえど現役なのだなあ。
そいや、dual-coding approachがdual-coding theoryになる境目というか'dual-coding theory'の初出は発見できず。
どうも本っぽいな・・・
Picture Superiority Effectんときに言及した本のうち、1971年の「Imagery and verbal processes.」がそれっぽい?
1986年の「Mental representation: A dual coding approach.」のGoogle books()で見られる限りでは4章タイトルがまんまdual-coding theoryなので、少なくともこれより前であるのは確か。
4章見ると、1971年のやつの考えにさらに手を加えたってことらしいから、これをdual-coding theoryの代表としてもよいかもしれない。
上であげたの以外では、
も候補にあげられそう。
つーかあまぞんにあるんだ・・・すげーなあまぞん。
・・・ただまあ躍起になって初出を探してもあんましメリットがないので、とりあえずdual-coding theoryの引用としてはPaivio (1986)かPaivio & Csapo(1973)でいいのかも・・・
・・・いいのかな?
図書館で本を見つけられたら初出を確認してみてもいいかも。
うーむ。思ったより奥が深いなdual-coding theoryは。
古典もあなどれないぜ!
ーーー追記ーーー
あまぞんさんの
にてなか見!検索が使えることに気づきました。
この中で検索をかけたら、ちゃんとdual-coding theoryって書いてある箇所がありました。
なのでdual-coding theoryの初出は1971年のこの本みたいです。
いやーネットべんりだなー。
謎が解けてよかったよかった。
というネタを思いついたのでRでのダネット法のやりかたをべんきょうする。
とくに今つかう必要はない。
ただこのタイトルを言えただけでまんぞくしている。
べんきょうの資料は
http://minato.sip21c.org/medstat/how-to-multcomp.pdf
で。
ダネット法そのものについては
http://aoki2.si.gunma-u.ac.jp/lecture/Average/Dunnett.html
を参照。
要するに、被験者間要因で多重比較するときに、水準のひとつが対照群だったらダネット法がよいということ。
プラセボ群と薬つかった群を比較する薬学系の研究とかまさにぴったり。
心理学で言うなら、メイン課題に干渉課題をつけるとかの実験デザインで、干渉なしと干渉課題A、干渉課題Bでパフォーマンスを比較したいっていうようなときにつかえるね。
二重課題とかアテンション系によくありそう。
んで、Rでダネット法やろうと思うと、Rのパッケージをインストールせねばならんらしいのでまずそいつを手に入れよう。
というわけで、Rを起動する。
起動したら、「パッケージ」のところから「パッケージをインストール」をくりっく。
これこのように。
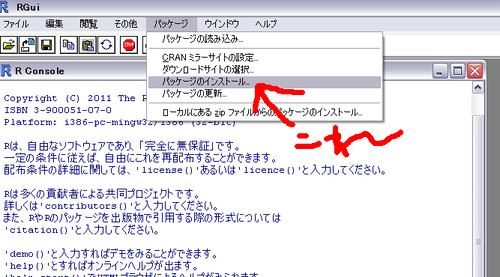
そしたらパッケージ名がずらずらならんだウィンドウが出てくるから、multicompというやつを選択する。
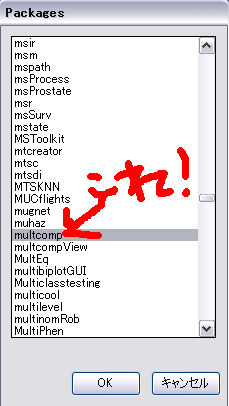
そしたらどこのサーバからダウンロードするか選べって言われるからてきとーに日本のやつを選ぶ。
すると勝手にダウンロードを始めてくれるので、ぼけっとした顔して待っとけばいい。
ダウンロードおわったら(おわったよメッセージないっぽい。ふだんのRの>が出てきたら完了かな?)、
require(multicomp)
か
library(multicomp)
かを打ち込めば準備完了。
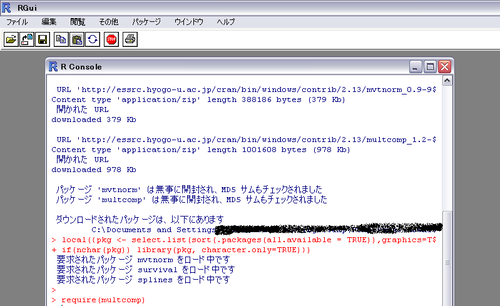
(パッケージおとした場所のパスははずかしいからかくした。)
で、ダネット法のやりかたを見るのに
example(recovery)
と書けばいいらしい。
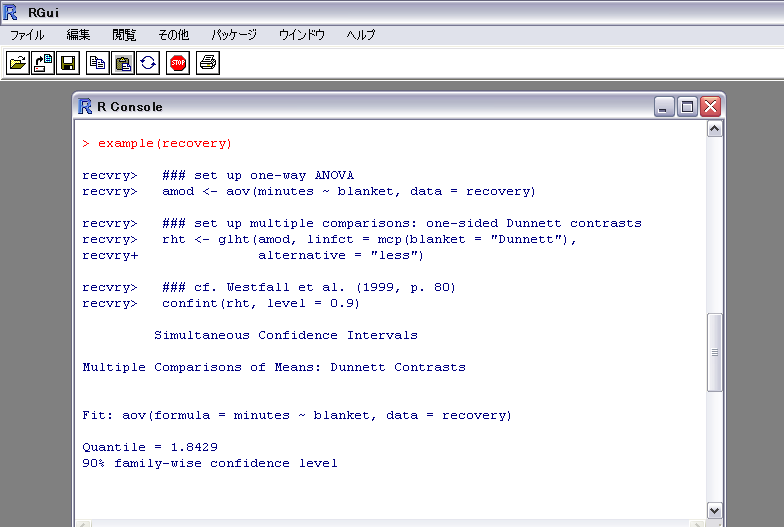
うむよくわからん。
資料をみると、glht()というのがダネット法する関数っぽい。
aovはANOVA用関数だから、まあ要するにANOVAして多重比較して、といういつもの流れをみせてくれてるようです。
せっかくなので資料にのってる例題をRでやってみよう。
まず例題のデータをぺいぺいっと。
bpdown <- data.frame(
medicine=factor(c(rep(1,5),rep(2,5),rep(3,5)), labels=c("placebo","old-m","new-m
")), #データフレームの行やら列やらラベルやらきめてる
#Rで日本語はいるとなんかへんな気がしたので変数名は変えたよ
sbpchange=c(5, 8, 3, 10, 15, 20, 12, 30, 16, 24, 31, 25, 17, 40, 23)) #データのなかみ
んで、
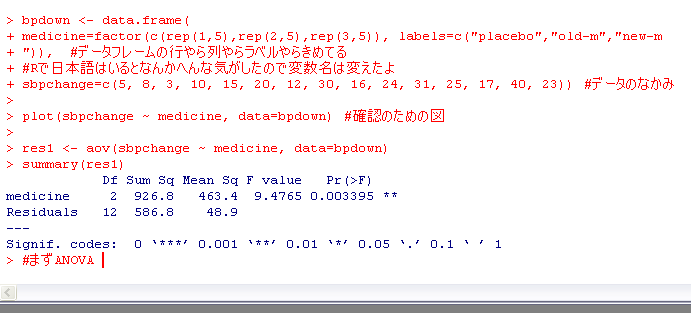
plot(sbpchange ~ medicine, data=bpdown)
をやっとくとこのデータを図示できる。
これこのように。
ほいで、
res1 <- aov(sbpchange ~ medicine, data=bpdown)
summary(res1)
でANOVAの結果がでる。
このとおり。
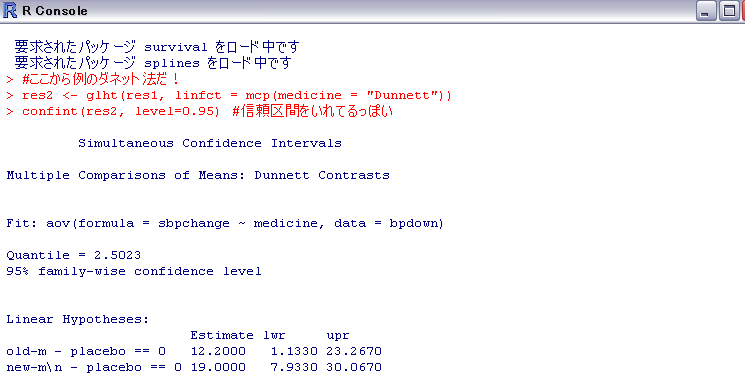
で、いよいよダネット法。
library(multcomp)
でmulticompをよみこんで
res2 <- glht(res1, linfct = mcp(medicine = "Dunnett"))
confint(res2, level=0.95) #信頼区間をいれてるっぽい
でダネット法の結果が出る。
summary(res2)
で結果まとめを出力するとこんなかんじ。
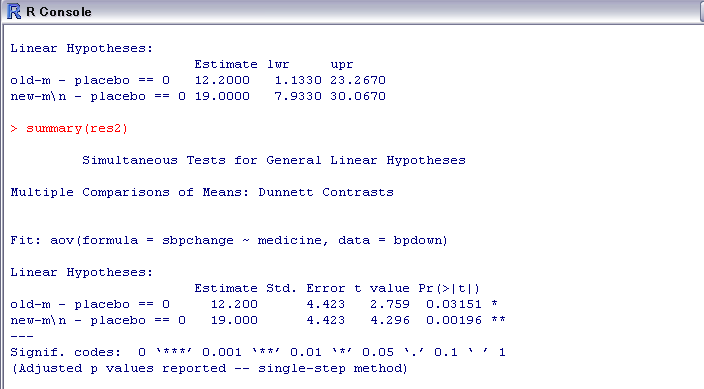
これでだいたいできるわけです。
これ一番最初の群をコントロール群に設定するようなってるぽいから、データつけるときにちゃんとそうなるよう配慮せなあかんのじゃないかな。
注意点はそれぐらいか。
まあタイトルネタつかえたからそれでいいや。
とくに今つかう必要はない。
ただこのタイトルを言えただけでまんぞくしている。
べんきょうの資料は
http://minato.sip21c.org/medstat/how-to-multcomp.pdf
で。
ダネット法そのものについては
http://aoki2.si.gunma-u.ac.jp/lecture/Average/Dunnett.html
を参照。
要するに、被験者間要因で多重比較するときに、水準のひとつが対照群だったらダネット法がよいということ。
プラセボ群と薬つかった群を比較する薬学系の研究とかまさにぴったり。
心理学で言うなら、メイン課題に干渉課題をつけるとかの実験デザインで、干渉なしと干渉課題A、干渉課題Bでパフォーマンスを比較したいっていうようなときにつかえるね。
二重課題とかアテンション系によくありそう。
んで、Rでダネット法やろうと思うと、Rのパッケージをインストールせねばならんらしいのでまずそいつを手に入れよう。
というわけで、Rを起動する。
起動したら、「パッケージ」のところから「パッケージをインストール」をくりっく。
これこのように。
そしたらパッケージ名がずらずらならんだウィンドウが出てくるから、multicompというやつを選択する。
そしたらどこのサーバからダウンロードするか選べって言われるからてきとーに日本のやつを選ぶ。
すると勝手にダウンロードを始めてくれるので、ぼけっとした顔して待っとけばいい。
ダウンロードおわったら(おわったよメッセージないっぽい。ふだんのRの>が出てきたら完了かな?)、
require(multicomp)
か
library(multicomp)
かを打ち込めば準備完了。
(パッケージおとした場所のパスははずかしいからかくした。)
で、ダネット法のやりかたを見るのに
example(recovery)
と書けばいいらしい。
うむよくわからん。
資料をみると、glht()というのがダネット法する関数っぽい。
aovはANOVA用関数だから、まあ要するにANOVAして多重比較して、といういつもの流れをみせてくれてるようです。
せっかくなので資料にのってる例題をRでやってみよう。
まず例題のデータをぺいぺいっと。
bpdown <- data.frame(
medicine=factor(c(rep(1,5),rep(2,5),rep(3,5)), labels=c("placebo","old-m","new-m
")), #データフレームの行やら列やらラベルやらきめてる
#Rで日本語はいるとなんかへんな気がしたので変数名は変えたよ
sbpchange=c(5, 8, 3, 10, 15, 20, 12, 30, 16, 24, 31, 25, 17, 40, 23)) #データのなかみ
んで、
plot(sbpchange ~ medicine, data=bpdown)
をやっとくとこのデータを図示できる。
これこのように。
ほいで、
res1 <- aov(sbpchange ~ medicine, data=bpdown)
summary(res1)
でANOVAの結果がでる。
このとおり。
で、いよいよダネット法。
library(multcomp)
でmulticompをよみこんで
res2 <- glht(res1, linfct = mcp(medicine = "Dunnett"))
confint(res2, level=0.95) #信頼区間をいれてるっぽい
でダネット法の結果が出る。
summary(res2)
で結果まとめを出力するとこんなかんじ。
これでだいたいできるわけです。
これ一番最初の群をコントロール群に設定するようなってるぽいから、データつけるときにちゃんとそうなるよう配慮せなあかんのじゃないかな。
注意点はそれぐらいか。
まあタイトルネタつかえたからそれでいいや。
今いろいろあってちょっとした質問紙っぽいデータをいじってるのですが、これっていわゆるX件法(リッカート尺度というらしい)のデータなんですよね。
心理学ではしれっと間隔尺度として平均とってANOVAにぶちこむのが主流ですが、それって本当に問題ないの?
と思ってぐぐってたらやっぱり議論になっているらしい。
http://elsur.jpn.org/mt/2012/01/001477.html
を読んだら、順序尺度をANOVAにぶちこんでもなんとかならんでもない印象を受けるけど、でもやっぱりなんか釈然としないものを感じる。
じゃあ、
http://okwave.jp/qa/q6892534.html
などを読んで「フリードマン検定」というやつをやればいいんじゃないかなと思った次第。
というわけで統計で有名なサイトの
http://aoki2.si.gunma-u.ac.jp/lecture/TwoWayANOVA/friedman.html
をふむふむと読んで、公開されているRのソースをつかってみたらわりと予想に近い結果になったのでめでたしめでたし。
あ、めでたしに至る前に、わたしのデータではp値がeつかうくらいのややこしい桁になったので、p値を出力するところにround()いれとくとわたしのよーなあほな文系にも結果が見やすくなるからおすすめ。
Rのround()については、
http://www.okada.jp.org/RWiki/?R%A5%D7%A5%ED%A5%B0%A5%E9%A5%DF%A5%F3%A5%B0Tips%C2%E7%C1%B4#q23fcdce
に詳しい説明があるよ。
要するに
round(p値を入れてる変数, 表示したい小数点の桁)
というのをp値出力前にかませてやればよいわけです。
あと順序尺度を多重比較にかけることについては
http://ir.lib.hiroshima-u.ac.jp/metadb/up/74006416/Kyoikugaku_kenkyuka_3_54_197_203_hayashi.pdf
のpdfがべんきょうになります。
どんなデータのときにどんな検定をすべきかチャートはよそのもっと統計詳しいサイトにいくらでもあるのでここでは特に言及しない。
まあ自分であったほうがいいなーと思ったらそのときに作ります。
うむ。
めでたしに限りなく近いなにか。
心理学ではしれっと間隔尺度として平均とってANOVAにぶちこむのが主流ですが、それって本当に問題ないの?
と思ってぐぐってたらやっぱり議論になっているらしい。
http://elsur.jpn.org/mt/2012/01/001477.html
を読んだら、順序尺度をANOVAにぶちこんでもなんとかならんでもない印象を受けるけど、でもやっぱりなんか釈然としないものを感じる。
じゃあ、
http://okwave.jp/qa/q6892534.html
などを読んで「フリードマン検定」というやつをやればいいんじゃないかなと思った次第。
というわけで統計で有名なサイトの
http://aoki2.si.gunma-u.ac.jp/lecture/TwoWayANOVA/friedman.html
をふむふむと読んで、公開されているRのソースをつかってみたらわりと予想に近い結果になったのでめでたしめでたし。
あ、めでたしに至る前に、わたしのデータではp値がeつかうくらいのややこしい桁になったので、p値を出力するところにround()いれとくとわたしのよーなあほな文系にも結果が見やすくなるからおすすめ。
Rのround()については、
http://www.okada.jp.org/RWiki/?R%A5%D7%A5%ED%A5%B0%A5%E9%A5%DF%A5%F3%A5%B0Tips%C2%E7%C1%B4#q23fcdce
に詳しい説明があるよ。
要するに
round(p値を入れてる変数, 表示したい小数点の桁)
というのをp値出力前にかませてやればよいわけです。
あと順序尺度を多重比較にかけることについては
http://ir.lib.hiroshima-u.ac.jp/metadb/up/74006416/Kyoikugaku_kenkyuka_3_54_197_203_hayashi.pdf
のpdfがべんきょうになります。
どんなデータのときにどんな検定をすべきかチャートはよそのもっと統計詳しいサイトにいくらでもあるのでここでは特に言及しない。
まあ自分であったほうがいいなーと思ったらそのときに作ります。
うむ。
めでたしに限りなく近いなにか。
PCをちょこっとだけ整理したら、Change Blindnessのデモが出てきた。
これは去年の非常勤でつかったやつだな。
作成コンセプトが「とりあえず動いてだいたいのかんじがつかめたらよし」なので、ざっくりVBで書いてある。
VBは時間制御が苦手なことで有名ですが、実験するんじゃなくてだいたいそれっぽく見えたら間に合うので気にせずVBで書いたのでした。
もともとは
http://azcog.blog.shinobi.jp/Entry/315/
で言及した
http://csclab.ucsd.edu/~alan/vision/change_blindness/
の刺激を使用したのだけど、このサイトJavaでのデモあるのなー。
ネット上でさくさくやれるならここでデモやったほうがよいと思う。
ネット使えない環境でとりあえずデモを動かすためだけのプログラムがこれ。
ダウンロード(zip)
もし興味あるという酔狂なひとがいたらおとして解凍してみてね。
VB環境あるひとはVB起動すればいいと思います。
てゆーか環境あるひとなら自分で書くよね。そうよね。
コードがもっさりなところには目つぶってくれるよね。そうだよね。
VB環境ないひとは、changeblindProject1.exeというファイルを実行してもらえばいけると思います。
つかいかた・注意
ということで。
ほんとによそで使えるのかはあとで検証する(←無責任)
これは去年の非常勤でつかったやつだな。
作成コンセプトが「とりあえず動いてだいたいのかんじがつかめたらよし」なので、ざっくりVBで書いてある。
VBは時間制御が苦手なことで有名ですが、実験するんじゃなくてだいたいそれっぽく見えたら間に合うので気にせずVBで書いたのでした。
もともとは
http://azcog.blog.shinobi.jp/Entry/315/
で言及した
http://csclab.ucsd.edu/~alan/vision/change_blindness/
の刺激を使用したのだけど、このサイトJavaでのデモあるのなー。
ネット上でさくさくやれるならここでデモやったほうがよいと思う。
ネット使えない環境でとりあえずデモを動かすためだけのプログラムがこれ。
ダウンロード(zip)
もし興味あるという酔狂なひとがいたらおとして解凍してみてね。
VB環境あるひとはVB起動すればいいと思います。
てゆーか環境あるひとなら自分で書くよね。そうよね。
コードがもっさりなところには目つぶってくれるよね。そうだよね。
VB環境ないひとは、changeblindProject1.exeというファイルを実行してもらえばいけると思います。
つかいかた・注意
- スタートボタンをクリックすると、Change blindnessが1試行始まります
- Change Blindnessなんで、変化を探してください
- 画像提供元が言うように、すっげーわかりやすいです。デモなんで
- 試行は5試行用意してあります
- 5試行やったあとスタートボタンクリックするとエラーはきよります。当たり前ですが。
- Endボタンをクリックすると終了できます
- 提示時間とブランクの時間は両方200ms(ただしVBが制御できる範囲で)です
- 本当は提示時間とブランクを好きなように設定できるようにしようかと思ったのですが、講義とかに使うときにいちいち設定画面出るのうざいかなーと思って省略しました。
- ごめんなさい、本当はめんどくさかっただけです
- まあVBならテキストボックス作ってテキスト取得してIntegerあたりに変換したらそれで済む話ですけどね
- それ言うなら試行の長さも自由に(ry
- すいません、めんどくさかっただけです
- この先必要か需要があればもうちょい自由なものに書き直すかも?
- そんな日が来るとはみじんこ思ってませんが
- でももしなんかあったら連絡してください
- でも、もっとがんばって探せばもっときれいで使い勝手のいいデモがどっかに落ちてるような気がする
- まあ自分用めもなんで自己満足でいいんです
ということで。
ほんとによそで使えるのかはあとで検証する(←無責任)
ろんぶん書いてて「あれ?これcountableやっけ?uncountableやっけ?」としょっちゅう迷ってしまう単語一覧めもを作ればちょっとはましかもしれないと思ったのでめも。
もともとが暗記の苦手なあほねこなので何回しらべてもわすれてしまうのですよ。
ちなみに出典はOxford Advanced Learners Dictionaryです。
http://oald8.oxfordlearnersdictionaries.com/
このオンライン英英辞書はつかいやすくわかりやすくてよし。
というわけでめも。
<performance>
われわれがつかうであろう意味(the act or process of performing a task, an action, etc)においてはuncountableでsingular
(informationみたいな扱いということか)
<similarity>
判定むずい。
似ている状態(the state of being like somebody/something but not exactly the same)をさすのであればuncountableでsingular
似ている特徴(a feature that things or people have that makes them like each other)をさすのであればcountable
まあでもわたしの場合ろんぶんで書くなら前者かなあ。後者を書くのならa common featureとかでよくね。いやわからんけど。
<familiarity>
uncountableでした。
まあ抽象的だもんね。
<background>
図地分離とか画像系の意味でつかうならcountable
文学的につかう場合に注意。
これまでの来し方みたいな意味(the circumstances or past events that help explain why something is how it is)でつかう場合countable
Attentionのあたっていないところみたいな意味(a position in which people are not paying attention to somebody/something or not as much attention as they are paying to somebody/something else)ならばsingular
<size>
どっちもあり。
要は自分の脳内で具象抽象どっちかってことか。
「大きさ」ではなく「大きいこと」(the large amount or extent of something)としてつかうのならばuncountable
<context>
どっちもあり。
・・・これうまいこと判断するのむずいな
<absence>
今いないという意味(the fact of somebody being away from a place where they are usually expected to be; the occasion or period of time when somebody is away)であればどっちもあり。
複数形ってどうつかうんだよ、と思ったら欠席とかが複数回あることをさすっぽい。
対して、そもそも存在していない、無いって意味(the fact of somebody/something not existing or not being available; a lack of something)だとuncountable
これに関連して
<presence>
なんとだいたいuncountable
「いない」ことは数えられても「いる」ことは数えられないのだろうか・・・?
特殊な用法として、a person or spirit that you cannot see but that you feel is nearな場合はcountableなんだそうな。
まあそんなものは「いる」ことが特殊だから回数を数えることもできるんだろう。ある種の現象だし。
んでもこの用法は論文にはつかわないだろうな。
とりあえず思いついたのはこれぐらい。
またあとで追記するかも。
もともとが暗記の苦手なあほねこなので何回しらべてもわすれてしまうのですよ。
ちなみに出典はOxford Advanced Learners Dictionaryです。
http://oald8.oxfordlearnersdictionaries.com/
このオンライン英英辞書はつかいやすくわかりやすくてよし。
というわけでめも。
<performance>
われわれがつかうであろう意味(the act or process of performing a task, an action, etc)においてはuncountableでsingular
(informationみたいな扱いということか)
<similarity>
判定むずい。
似ている状態(the state of being like somebody/something but not exactly the same)をさすのであればuncountableでsingular
似ている特徴(a feature that things or people have that makes them like each other)をさすのであればcountable
まあでもわたしの場合ろんぶんで書くなら前者かなあ。後者を書くのならa common featureとかでよくね。いやわからんけど。
<familiarity>
uncountableでした。
まあ抽象的だもんね。
<background>
図地分離とか画像系の意味でつかうならcountable
文学的につかう場合に注意。
これまでの来し方みたいな意味(the circumstances or past events that help explain why something is how it is)でつかう場合countable
Attentionのあたっていないところみたいな意味(a position in which people are not paying attention to somebody/something or not as much attention as they are paying to somebody/something else)ならばsingular
<size>
どっちもあり。
要は自分の脳内で具象抽象どっちかってことか。
「大きさ」ではなく「大きいこと」(the large amount or extent of something)としてつかうのならばuncountable
<context>
どっちもあり。
・・・これうまいこと判断するのむずいな
<absence>
今いないという意味(the fact of somebody being away from a place where they are usually expected to be; the occasion or period of time when somebody is away)であればどっちもあり。
複数形ってどうつかうんだよ、と思ったら欠席とかが複数回あることをさすっぽい。
対して、そもそも存在していない、無いって意味(the fact of somebody/something not existing or not being available; a lack of something)だとuncountable
これに関連して
<presence>
なんとだいたいuncountable
「いない」ことは数えられても「いる」ことは数えられないのだろうか・・・?
特殊な用法として、a person or spirit that you cannot see but that you feel is nearな場合はcountableなんだそうな。
まあそんなものは「いる」ことが特殊だから回数を数えることもできるんだろう。ある種の現象だし。
んでもこの用法は論文にはつかわないだろうな。
とりあえず思いついたのはこれぐらい。
またあとで追記するかも。
カレンダー
| 03 | 2025/04 | 05 |
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
カテゴリ説明
がっつり:論文や研究関連をがっつり。
びっくり:科学ニュースでびっくり。
まったり:空想科学などでまったり。
ばっかり:デザイン系自己満足ばっかり。
ほっこり:お茶を嗜んでほっこり。
最新コメント
※SPAMが多いのでhttpを含むコメントと英語のみのコメントを禁止しました※

最新記事
(05/08)
(04/24)
(04/10)
(02/03)
(11/01)
最新トラックバック
プロフィール
HN:
az
性別:
非公開
自己紹介:
興味のあるトピックス
分野は視覚認知。視知覚にがて。
あと記憶全般。
カテゴリ (semanticsか?) とかも。
最近デコーディングが気になる。
でも基本なんでもこい。
好奇心は悪食。
好きな作家(敬称略)
川上弘美
小林秀雄
津原泰水
森茉莉
レイ・ブラッドベリ
イタロ・カルヴィーノ
グレッグ・イーガン
シオドア・スタージョン
分野は視覚認知。視知覚にがて。
あと記憶全般。
カテゴリ (semanticsか?) とかも。
最近デコーディングが気になる。
でも基本なんでもこい。
好奇心は悪食。
好きな作家(敬称略)
川上弘美
小林秀雄
津原泰水
森茉莉
レイ・ブラッドベリ
イタロ・カルヴィーノ
グレッグ・イーガン
シオドア・スタージョン
バーコード
ブログ内検索
最古記事
(08/05)
(08/16)
(08/19)
(08/19)
(08/21)
カウンター
フリーエリア
PR