めもめも ...〆(。_。)
認知心理学・認知神経科学とかいろいろなはなし。 あるいは科学と空想科学の狭間で微睡む。

×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
古典再訪シリーズ(シリーズ化するほどやってないというつっこみは不可)。
今回テーマにするPicture Superiority Effectというのは、単純にいえば「単語よりも絵のほうがおぼえやすい」という話です。
アイディアとしてはシンプル。実にシンプル。
だけどシンプルゆえにいろんな要素が考慮されてなくて(たとえば単語ひとつと絵一枚が「等価」といえるのか?とか)、それゆえにいまだ議論されている点があったり、古典だから教科書どおりのことしか覚えていない非視覚記憶研究者とぶつかることがあったりするわけです。
じゃあとりあえず根っこのところを確認しておこうぜ!というのが今回の動機。
ちうかなんか衝突でもない限りわざわざ古典再訪とかせんわな。このものぐさなわたしが。
まあそんなことはおいておいて、とりあえず初出文献あたりからチェックしていきましょう。
Picture Superiority Effect関連でよく引用されているのがPaivioの本。
一番古いっぽいのは1971年の「Imagery and verbal processes.」という本。
ぐぐってもあんまし情報がないけどあまぞんさんにはたぶん再販本っぽいのが売ってる。
すげーなあまぞん。
ひとつは「Imagery in recall and recognition.」というタイトルの1976年の本。
PubMedにもひっかからないしアマゾンにもないのでAPAのをのせとく
http://psycnet.apa.org/psycinfo/1977-11959-003
んでもひとつ、「Mental representation: A dual coding approach.」という1986年の本。
こいつはGoogle Booksで中身がちらっと読める。
http://books.google.co.jp/books?hl=ja&lr=&id=hLGmKkh_4K8C&oi=fnd&pg=PA3&dq=PAIVIO+Mental+representation:+A+dual+coding+approach&ots=B2CU7Clsor&sig=gmuujy9D86RghqxSDoWGZqtqyDs#v=onepage&q=PAIVIO%20Mental%20representation%3A%20A%20dual%20coding%20approach&f=false
んであまぞんさんでも売ってる。
あまぞんさんわりといろいろ売ってるなー。いまさらだけど。
んが、こういう本は図書館にもあったりなかったりだし重いし長いしざっとチェックするには骨が折れる。いろんな意味で。
なのでやっぱり論文で読みたいところ。
とりあえず論文としておさえておきたいのは以下。
まず(おそらく)初出っぽい論文。
Paivio, A., Rogers, T. B., & Smythe, P. C. Why are pictures easier to recall than words? Psychonomic Science, 1968, 11, 137-138.
古すぎて電子ジャーナルねえー。
ぐぐってもあんまし出てこねえー。
一応大学図書館にはあるっぽいので今度ひさしぶりに書庫探検してみよう。
初出候補その2.
Paivio, A. Mental imagery in associative learning and memory. Psychological Review, 1969, 76, 241-263.
http://psycnet.apa.org/psycinfo/1969-10753-001
これもあんまし検索にあたらないのだけど、運よく古くても電子ジャーナル化されているやつだったんで論文そのものは手に入れることができた。
んでPicture Superiority Effectをタイトルに謳っているのが
Paivio, A., & Csapo, K. (1973). Picture superiority in free recall: Imagery or dual coding. Cognitive Psychology, 5, 176-206.
http://www.sciencedirect.com/science/article/pii/0010028573900327
と
Nelson, D. L., Reed, V. S., & Walling, J. R. (1976). Pictorial Superiority Effect. Journal of Experimental Psychology: Human Learning and Memory, 2(5), 523-528.
http://www.ncbi.nlm.nih.gov/pubmed/1003125
(どうでもいいけどようやくPubMedにデータのある文献が出たよ・・・マイナー古典なのかこのへんは)
ということはこの3つを押さえておけば「古典再訪」としては一応さまになるわけだ。
この3つのざっと読みはつづきのところで。
今回テーマにするPicture Superiority Effectというのは、単純にいえば「単語よりも絵のほうがおぼえやすい」という話です。
アイディアとしてはシンプル。実にシンプル。
だけどシンプルゆえにいろんな要素が考慮されてなくて(たとえば単語ひとつと絵一枚が「等価」といえるのか?とか)、それゆえにいまだ議論されている点があったり、古典だから教科書どおりのことしか覚えていない非視覚記憶研究者とぶつかることがあったりするわけです。
じゃあとりあえず根っこのところを確認しておこうぜ!というのが今回の動機。
ちうかなんか衝突でもない限りわざわざ古典再訪とかせんわな。このものぐさなわたしが。
まあそんなことはおいておいて、とりあえず初出文献あたりからチェックしていきましょう。
Picture Superiority Effect関連でよく引用されているのがPaivioの本。
一番古いっぽいのは1971年の「Imagery and verbal processes.」という本。
ぐぐってもあんまし情報がないけどあまぞんさんにはたぶん再販本っぽいのが売ってる。
すげーなあまぞん。
ひとつは「Imagery in recall and recognition.」というタイトルの1976年の本。
PubMedにもひっかからないしアマゾンにもないのでAPAのをのせとく
http://psycnet.apa.org/psycinfo/1977-11959-003
んでもひとつ、「Mental representation: A dual coding approach.」という1986年の本。
こいつはGoogle Booksで中身がちらっと読める。
http://books.google.co.jp/books?hl=ja&lr=&id=hLGmKkh_4K8C&oi=fnd&pg=PA3&dq=PAIVIO+Mental+representation:+A+dual+coding+approach&ots=B2CU7Clsor&sig=gmuujy9D86RghqxSDoWGZqtqyDs#v=onepage&q=PAIVIO%20Mental%20representation%3A%20A%20dual%20coding%20approach&f=false
んであまぞんさんでも売ってる。
あまぞんさんわりといろいろ売ってるなー。いまさらだけど。
んが、こういう本は図書館にもあったりなかったりだし重いし長いしざっとチェックするには骨が折れる。いろんな意味で。
なのでやっぱり論文で読みたいところ。
とりあえず論文としておさえておきたいのは以下。
まず(おそらく)初出っぽい論文。
Paivio, A., Rogers, T. B., & Smythe, P. C. Why are pictures easier to recall than words? Psychonomic Science, 1968, 11, 137-138.
古すぎて電子ジャーナルねえー。
ぐぐってもあんまし出てこねえー。
一応大学図書館にはあるっぽいので今度ひさしぶりに書庫探検してみよう。
初出候補その2.
Paivio, A. Mental imagery in associative learning and memory. Psychological Review, 1969, 76, 241-263.
http://psycnet.apa.org/psycinfo/1969-10753-001
これもあんまし検索にあたらないのだけど、運よく古くても電子ジャーナル化されているやつだったんで論文そのものは手に入れることができた。
んでPicture Superiority Effectをタイトルに謳っているのが
Paivio, A., & Csapo, K. (1973). Picture superiority in free recall: Imagery or dual coding. Cognitive Psychology, 5, 176-206.
http://www.sciencedirect.com/science/article/pii/0010028573900327
と
Nelson, D. L., Reed, V. S., & Walling, J. R. (1976). Pictorial Superiority Effect. Journal of Experimental Psychology: Human Learning and Memory, 2(5), 523-528.
http://www.ncbi.nlm.nih.gov/pubmed/1003125
(どうでもいいけどようやくPubMedにデータのある文献が出たよ・・・マイナー古典なのかこのへんは)
ということはこの3つを押さえておけば「古典再訪」としては一応さまになるわけだ。
この3つのざっと読みはつづきのところで。

ここんところ毎日さむくてしにそう。
さむくてやるきのでないときってみんなどうやって対処してるんだろう。
温もってやるきがばりばり出るお茶とかあればいいのにな。
こう寒いと紅茶もすぐ冷えるんだ。
やっぱティーコジーを用意すべきかな。
ミシン買って無駄に凝ったティーコジーとか作りたい。裁縫にがてだけど。
発想がむちゃくちゃインドア。
さむくてやるきがでないけどおべんきょうしまふ。
ただしくはメシマズ帝国で習ったことの復習なんだけど、そいやこっちにめもってなかった気がするので、めもりながらの復習。
今回復習するのは、Latent Semantic Analysisという言語学っぽい手法について。
略称LSA。
ざっくばらんに言うと言語の共起頻度しらべるやつ。
本当のこと言うと、RでLSAのためのツールとか作られてるから勉強がてらRでLSAできるコード書いてそれもめもにしとこうと思ったけどテキストマイニングのめんどくささに嫌気が差して放置。
本気でLSAやることになったら本腰いれてとりかかるかも。
まあとりあえずの復習ということで。
さむくてやるきのでないときってみんなどうやって対処してるんだろう。
温もってやるきがばりばり出るお茶とかあればいいのにな。
こう寒いと紅茶もすぐ冷えるんだ。
やっぱティーコジーを用意すべきかな。
ミシン買って無駄に凝ったティーコジーとか作りたい。裁縫にがてだけど。
発想がむちゃくちゃインドア。
さむくてやるきがでないけどおべんきょうしまふ。
ただしくはメシマズ帝国で習ったことの復習なんだけど、そいやこっちにめもってなかった気がするので、めもりながらの復習。
今回復習するのは、Latent Semantic Analysisという言語学っぽい手法について。
略称LSA。
ざっくばらんに言うと言語の共起頻度しらべるやつ。
本当のこと言うと、RでLSAのためのツールとか作られてるから勉強がてらRでLSAできるコード書いてそれもめもにしとこうと思ったけどテキストマイニングのめんどくささに嫌気が差して放置。
本気でLSAやることになったら本腰いれてとりかかるかも。
まあとりあえずの復習ということで。
長らく研究費のまづしい(「貧しい」なんてレベルではないのである。戦前仮名遣いにしたくなる「まづしさ」なのである)生活をしてきたせいで、わりとなんでもフリーソフトで済ませる癖がある。
分析ならRとか。
ちょっとした画像の加工ならGIMPとか。
んでGIMPってデフォルトではテキスト縦書きできないんですね。
そりゃ困った。
って人のために縦書きできるスクリプトが公開されているんだけど↓
http://ameblo.jp/kazukiokumura/entry-10500032065.html
これがなかなか使いづらい。
ちっこいネットブックだとウィンドウが画面に収まりきらないし。
んで、それよりも便利なのが、GIMPのテキストを縦書きに変換してくれるツール。
http://gimp.ironsand.net/2011/gimp-tategaki-auto/
ZIPをダウンロードして解凍して、スクリプト置き場(わたしの場合はProgram Files→GIMP-2.0→share→gimp→2.0→scriptsだった)に中身をコピペしてからGIMPを起動すれば使えるようになるよ!
いつもと同じようにテキスト書いてそれを選択した状態でツールから「縦書きふ~(Auto)」というのを選択すれば縦書きに変換してもらえる。
べんりべんり。
にしても、あたまわるいネットブックではちょっとフォントいじろうとフォントの海にもぐると途端にフリーズ&強制終了するのが困る。
これの対処方法はなんかないかしら。
分析ならRとか。
ちょっとした画像の加工ならGIMPとか。
んでGIMPってデフォルトではテキスト縦書きできないんですね。
そりゃ困った。
って人のために縦書きできるスクリプトが公開されているんだけど↓
http://ameblo.jp/kazukiokumura/entry-10500032065.html
これがなかなか使いづらい。
ちっこいネットブックだとウィンドウが画面に収まりきらないし。
んで、それよりも便利なのが、GIMPのテキストを縦書きに変換してくれるツール。
http://gimp.ironsand.net/2011/gimp-tategaki-auto/
ZIPをダウンロードして解凍して、スクリプト置き場(わたしの場合はProgram Files→GIMP-2.0→share→gimp→2.0→scriptsだった)に中身をコピペしてからGIMPを起動すれば使えるようになるよ!
いつもと同じようにテキスト書いてそれを選択した状態でツールから「縦書きふ~(Auto)」というのを選択すれば縦書きに変換してもらえる。
べんりべんり。
にしても、あたまわるいネットブックではちょっとフォントいじろうとフォントの海にもぐると途端にフリーズ&強制終了するのが困る。
これの対処方法はなんかないかしら。
なんかMendeleyでもうちょっと効率よく論文をシェアする必要が出てきたっぽい。
以前やったやりかた(http://azcog.blog.shinobi.jp/Entry/208/)は、まあ1人ちょっと論文ぺろっと見せればそれで用がすむというものだったのだけど、複数人相手にやらかすのであればいちいちContactを作るよりかはGroupをつくったほうがべんりっぽい。
なのでGroupつくってみた。
1)まずWebのほうのMendeleyにログインする。
2)左上の Dashboard/My Library/Papers/Groups/People タブからGroupsを選ぶ。
3)右に Create a new group というみどりの四角いぼたんがあるのでそれをぽちり
4)図のような画面で公開設定を決める。

→Anyone can join this group (承認なしで参加できる)
→Anyone can ask to join this group (承認つきで参加できる)
→Private Group (こっちから呼びかけない限り参加できない)
5)グループ名などをてきとーにでっちあげる
これでグループは作られた。
んで、Mendeley Desktop呼び出して、Groupsのところに自分がつくったグループあるかを確認。
このグループを選択した状態で、シェアしたい論文をてけとーにドラッグアンドドロップしてSync Libraryをぽちっておけば大丈夫っぽい。
まあこのままだと自分1人のぼっちグループになってしまってわびしいので、他のひとをこのグループに呼びつけることにします。
1)ログインしたWebのMendeleyに戻る。
2)左上の Dashboard/My Library/Papers/Groups/People タブからGroupsを選ぶ。
3)My groupsのところにさっき作ったグループがあるからそれをぽちっとくりっく。
4)左に Overview/Papers/Members/Settings というタブが出るからSettingsを選ぶ。
5)下のほうにMembersの項目があって、AddとInviteというボタンがある。
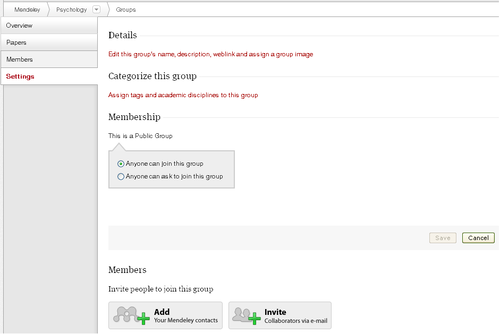
呼びつける相手がMendeleyアカウントを持っているのなら、Addボタンを押して現れるウィンドウにアカウント名を入れるだけでよし。相手がアカウントとかなさげだったら、Inviteボタンでメーラーが出るのでメールしましょう。
今回はアカウントもち相手だったので楽でした。
6)相手のひまなときにGroup参加を承認してもらう。(こっちが送ったのは「招待」なのでAnyone can join this groupだろうと招待が承認されんことにはどうしようもない)
まあこんなかんじです。かんたんですね。
いちおうの追記ってことで。
以前やったやりかた(http://azcog.blog.shinobi.jp/Entry/208/)は、まあ1人ちょっと論文ぺろっと見せればそれで用がすむというものだったのだけど、複数人相手にやらかすのであればいちいちContactを作るよりかはGroupをつくったほうがべんりっぽい。
なのでGroupつくってみた。
1)まずWebのほうのMendeleyにログインする。
2)左上の Dashboard/My Library/Papers/Groups/People タブからGroupsを選ぶ。
3)右に Create a new group というみどりの四角いぼたんがあるのでそれをぽちり
4)図のような画面で公開設定を決める。
→Anyone can join this group (承認なしで参加できる)
→Anyone can ask to join this group (承認つきで参加できる)
→Private Group (こっちから呼びかけない限り参加できない)
5)グループ名などをてきとーにでっちあげる
これでグループは作られた。
んで、Mendeley Desktop呼び出して、Groupsのところに自分がつくったグループあるかを確認。
このグループを選択した状態で、シェアしたい論文をてけとーにドラッグアンドドロップしてSync Libraryをぽちっておけば大丈夫っぽい。
まあこのままだと自分1人のぼっちグループになってしまってわびしいので、他のひとをこのグループに呼びつけることにします。
1)ログインしたWebのMendeleyに戻る。
2)左上の Dashboard/My Library/Papers/Groups/People タブからGroupsを選ぶ。
3)My groupsのところにさっき作ったグループがあるからそれをぽちっとくりっく。
4)左に Overview/Papers/Members/Settings というタブが出るからSettingsを選ぶ。
5)下のほうにMembersの項目があって、AddとInviteというボタンがある。
呼びつける相手がMendeleyアカウントを持っているのなら、Addボタンを押して現れるウィンドウにアカウント名を入れるだけでよし。相手がアカウントとかなさげだったら、Inviteボタンでメーラーが出るのでメールしましょう。
今回はアカウントもち相手だったので楽でした。
6)相手のひまなときにGroup参加を承認してもらう。(こっちが送ったのは「招待」なのでAnyone can join this groupだろうと招待が承認されんことにはどうしようもない)
まあこんなかんじです。かんたんですね。
いちおうの追記ってことで。
ちまちまいじっていたRのプログラムのうち1つがちゃんと通るようになったので晒し上げ。
今回作ったのは、てけとーなデータからコサイン類似度を計算するもの。
自作関数とかめんどいので中身べた貼り。
「動きゃいーのよ」が開発理念ゆえに、だいぶぶさいくなコードですが自分が満足すればそれでいいのです。
参考にしたのはここ(http://isyus2.yz.yamagata-u.ac.jp/xoops/modules/pukiwiki/index.php?cmd=read&page=R%B8%C0%B8%EC%A4%CE%A5%E1%A5%E2%BD%F1%A4%AD&word=)。
data <- read.csv("調べるデータの名前.csv", header =T)
#ちなみにデータは、1行目に項目名、列ごとに各項目のデータが入るようにしてある
labeldata <- read.csv("Labels.csv", header =T)
names(labeldata)
#いろいろいじるので、めんどくさくなってラベル用にラベル(項目名)だけ書いたCSV用意しちゃった。てへ。
#ちなみに元データから抜き出す方法だと行番号がずれて、修正しようにも収拾つかなくなったので苦肉の策。
distmat1 <- diag(ncol(data))
#コサイン類似度出力用。おなじものは1になるのであらかじめ単位行列として作る
#コサイン類似度を計算。型変換しないとつまるので、ぶさいくながらこまめに変数にする
for (i in 2:nrow(distmat1)) {
for (j in 1: (i -1)) {
temp1 <- as.matrix(data[ ,j])
temp2 <- as.matrix(data[ ,i])
tempdot <- crossprod(temp1, temp2)
tempprod1 <- as.numeric(crossprod(temp1))
tempprod2 <- as.numeric(crossprod(temp2))
tempcos <- tempdot /sqrt(tempprod1 * tempprod2)
distmat1[i, j] <- tempcos
}
}
#計算していない上半分を下半分からコピーして対称行列にする
distmat2 <- distmat1 + t(distmat1)
diag(distmat2) <- diag(distmat2)/2
#クラスター分析用にコサイン類似度の距離に変換(要するに1から引き算)
onemat <- matrix(1, ncol(distmat2), nrow(distmat2))
#引き算用1だけ行列
distmat3 <- onemat - distmat2
#これが距離行列になる
#おまけのクラスター分析
(このへんはこの過去めもを参照)
AD <- as.dist (distmat3)
result1 <- hclust(AD, method ="ward")
plot(result1, labels=labeldata$ラベル用のデータのラベル)
#このlabelsをつけておかないと、plotが数字(order)だけの図になってしまう
だいたいこんなかんじ。
ちなみに、Rのdist関数はユークリッド距離と最大距離とマンハッタン距離とミンコフスキー距離と、あとなんか
今回作ったのは、てけとーなデータからコサイン類似度を計算するもの。
自作関数とかめんどいので中身べた貼り。
「動きゃいーのよ」が開発理念ゆえに、だいぶぶさいくなコードですが自分が満足すればそれでいいのです。
参考にしたのはここ(http://isyus2.yz.yamagata-u.ac.jp/xoops/modules/pukiwiki/index.php?cmd=read&page=R%B8%C0%B8%EC%A4%CE%A5%E1%A5%E2%BD%F1%A4%AD&word=)。
data <- read.csv("調べるデータの名前.csv", header =T)
#ちなみにデータは、1行目に項目名、列ごとに各項目のデータが入るようにしてある
labeldata <- read.csv("Labels.csv", header =T)
names(labeldata)
#いろいろいじるので、めんどくさくなってラベル用にラベル(項目名)だけ書いたCSV用意しちゃった。てへ。
#ちなみに元データから抜き出す方法だと行番号がずれて、修正しようにも収拾つかなくなったので苦肉の策。
distmat1 <- diag(ncol(data))
#コサイン類似度出力用。おなじものは1になるのであらかじめ単位行列として作る
#コサイン類似度を計算。型変換しないとつまるので、ぶさいくながらこまめに変数にする
for (i in 2:nrow(distmat1)) {
for (j in 1: (i -1)) {
temp1 <- as.matrix(data[ ,j])
temp2 <- as.matrix(data[ ,i])
tempdot <- crossprod(temp1, temp2)
tempprod1 <- as.numeric(crossprod(temp1))
tempprod2 <- as.numeric(crossprod(temp2))
tempcos <- tempdot /sqrt(tempprod1 * tempprod2)
distmat1[i, j] <- tempcos
}
}
#計算していない上半分を下半分からコピーして対称行列にする
distmat2 <- distmat1 + t(distmat1)
diag(distmat2) <- diag(distmat2)/2
#クラスター分析用にコサイン類似度の距離に変換(要するに1から引き算)
onemat <- matrix(1, ncol(distmat2), nrow(distmat2))
#引き算用1だけ行列
distmat3 <- onemat - distmat2
#これが距離行列になる
#おまけのクラスター分析
(このへんはこの過去めもを参照)
AD <- as.dist (distmat3)
result1 <- hclust(AD, method ="ward")
plot(result1, labels=labeldata$ラベル用のデータのラベル)
#このlabelsをつけておかないと、plotが数字(order)だけの図になってしまう
だいたいこんなかんじ。
ちなみに、Rのdist関数はユークリッド距離と最大距離とマンハッタン距離とミンコフスキー距離と、あとなんか
canberraとかbinaryとかいうのならデフォルトで対応しているそうな。
http://127.0.0.1:23392/library/stats/html/dist.html
まあ要するにそれ以外なら自力でなんとかせんといかんということかいのう。
まあいいや。
だいたいでいいや。
カレンダー
| 03 | 2025/04 | 05 |
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
カテゴリ説明
がっつり:論文や研究関連をがっつり。
びっくり:科学ニュースでびっくり。
まったり:空想科学などでまったり。
ばっかり:デザイン系自己満足ばっかり。
ほっこり:お茶を嗜んでほっこり。
最新コメント
※SPAMが多いのでhttpを含むコメントと英語のみのコメントを禁止しました※

最新記事
(05/08)
(04/24)
(04/10)
(02/03)
(11/01)
最新トラックバック
プロフィール
HN:
az
性別:
非公開
自己紹介:
興味のあるトピックス
分野は視覚認知。視知覚にがて。
あと記憶全般。
カテゴリ (semanticsか?) とかも。
最近デコーディングが気になる。
でも基本なんでもこい。
好奇心は悪食。
好きな作家(敬称略)
川上弘美
小林秀雄
津原泰水
森茉莉
レイ・ブラッドベリ
イタロ・カルヴィーノ
グレッグ・イーガン
シオドア・スタージョン
分野は視覚認知。視知覚にがて。
あと記憶全般。
カテゴリ (semanticsか?) とかも。
最近デコーディングが気になる。
でも基本なんでもこい。
好奇心は悪食。
好きな作家(敬称略)
川上弘美
小林秀雄
津原泰水
森茉莉
レイ・ブラッドベリ
イタロ・カルヴィーノ
グレッグ・イーガン
シオドア・スタージョン
バーコード
ブログ内検索
最古記事
(08/05)
(08/16)
(08/19)
(08/19)
(08/21)
カウンター
フリーエリア
PR